数据结构--队列
本文写于 2020 年 3 月 21 日,2022 年 3 月 6 日重新整理
本文写于 2020 年 3 月 21 日,2022 年 3 月 6 日重新整理
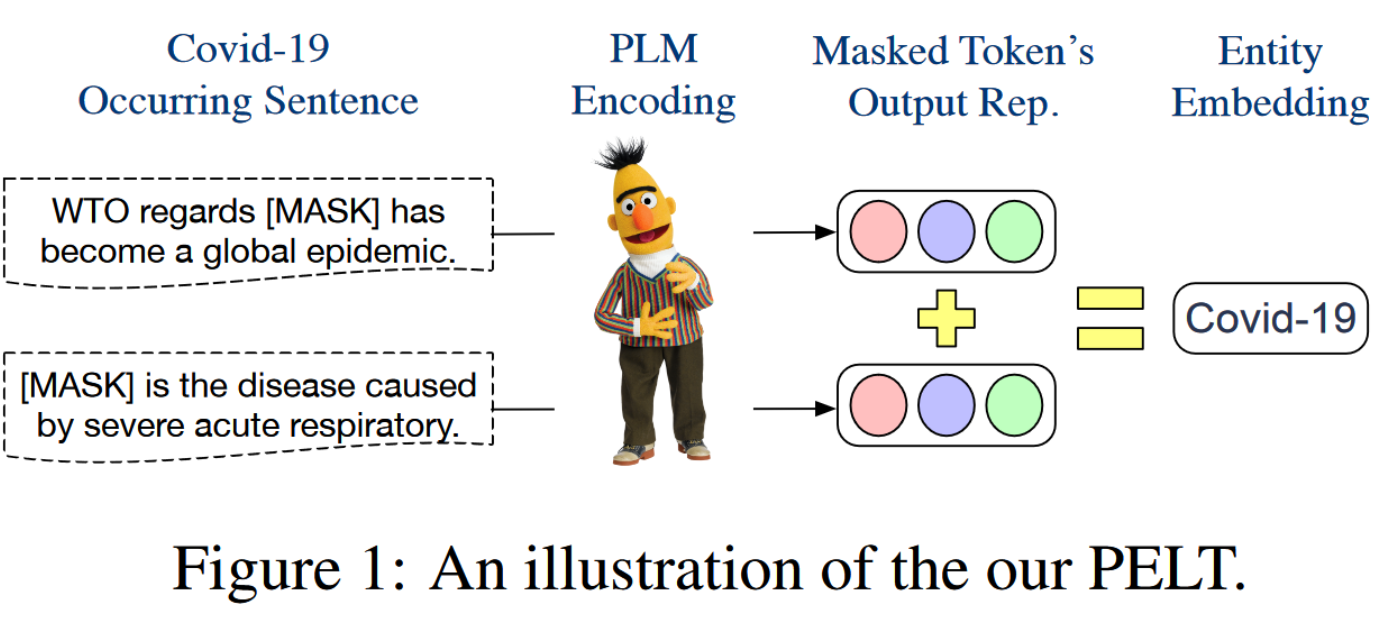
作者提出一种向 PLM 注入实体知识的简单方法:首先利用 PLM 为实体提及生成的表征预构建实体嵌入查找表,并在模型推理时修改嵌入层,将实体提及的嵌入直接替换为查找表中的嵌入,实现无特殊预训练的条件下向 PLM 注入实体知识。
本文写于 2020 年 3 月 19 日,2022 年 3 月 5 日重新整理
本文写于 2020 年 3 月 19 日,2022 年 3 月 5 日重新整理
文章主要研究向预训练语言模型中注入知识的方法,现存的工作主要是通过更新预训练模型参数的方式向模型注入知识(即 fine-tune 的方式)。但是这种参数更新过程会将整个模型的参数向新注入的知识上偏移,导致之前注入的知识被削弱或冲刷。作者提出的 K-Adapter 结构,通过将不同的知识分别注入到不同的 Adapter 中实现知识的持续注入,同时 Adapter 的参数量远小于预训练模型,在知识注入的过程中更加经济。
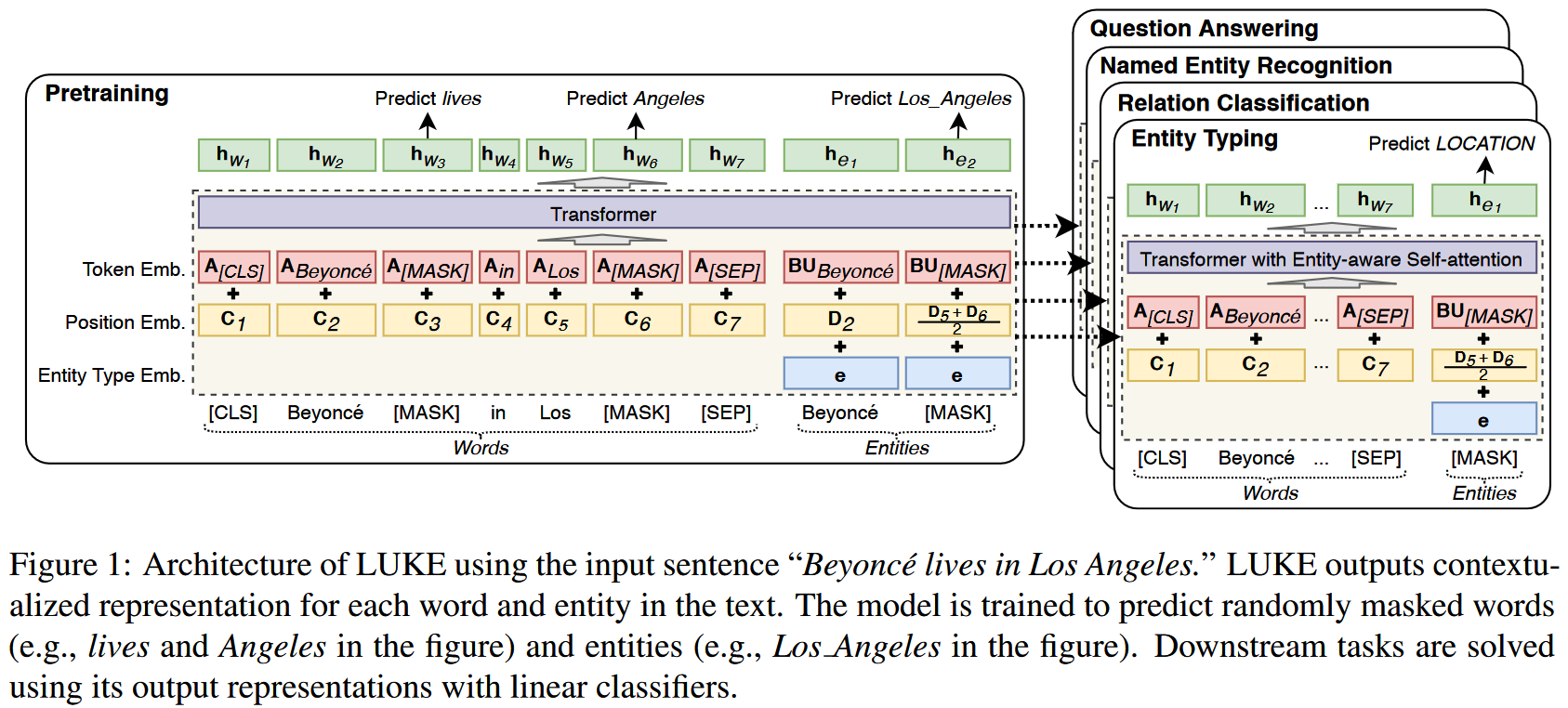
作者提出一种实体表征方法,通过在预训练 Transformer Encoder 模型时将实体看作独立的 token 来为实体生成表征。作者提出类似于 MLM 的预训练目标,首先将语料中的实体文本提取并放在语句末端,然后以一定的比例将实体替换为 ,并训练模型预测被遮罩的实体。为了提升效果,作者为放在语句末端的实体设计了特殊的实体 positional embedding,同时在 Encoder 模型的基础上添加 entity-aware self-attention mechanism 来增强模型对 token type(entity or word) 的感知。作者在多个数据集多个实体相关的任务上进行了实验。
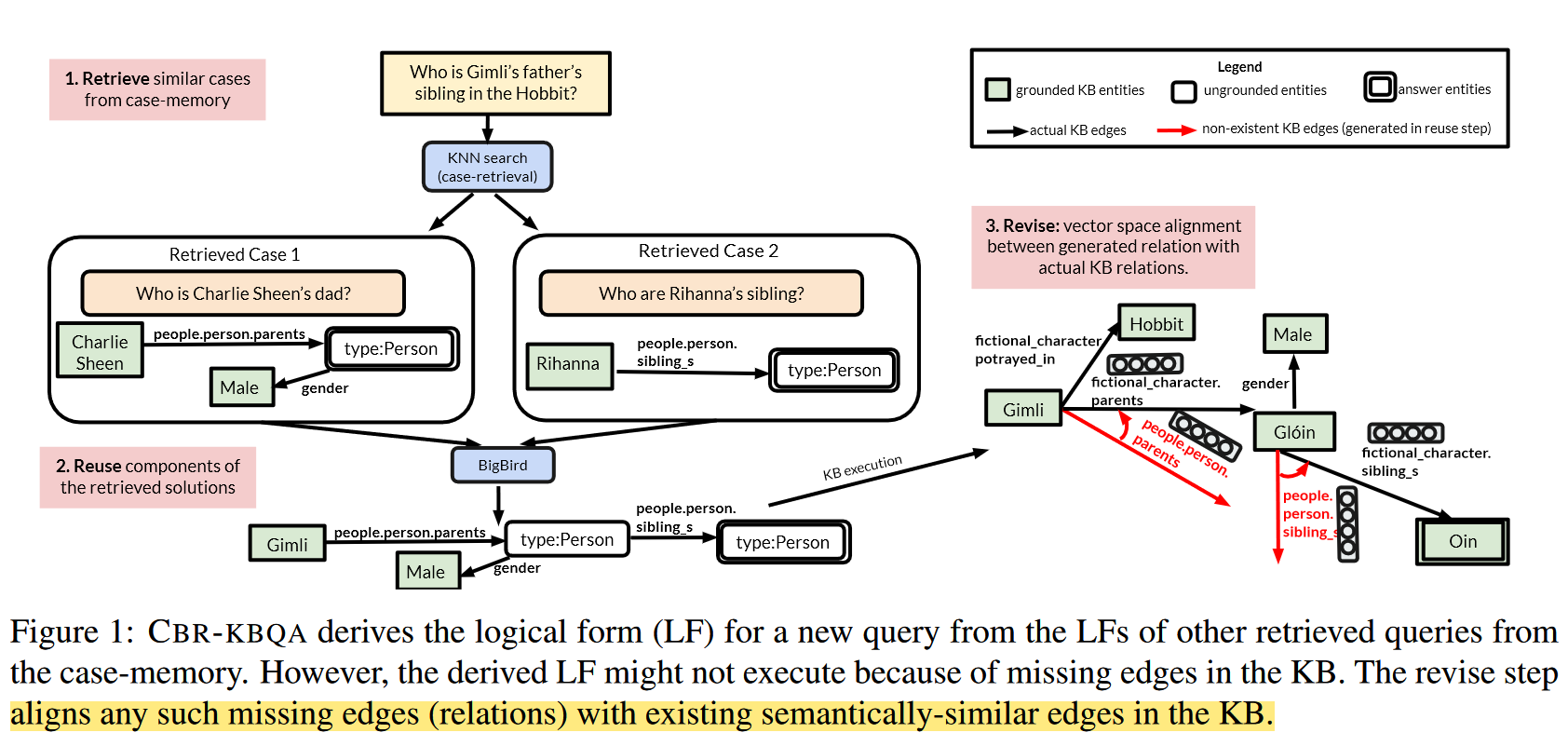
作者提出一种 基于案例的推理(Case-Based Reasoning, CBR) 解决 KBQA 问题的模型 CBR-KBQA。文章关注于语义解析方式,根据自然语言问题文本生成可执行的逻辑表达式 (SparQL),并在知识图谱上执行该逻辑表达式获得答案。
CBR-KBQA 由三部分组成:
首先通过 Retrieval Module 选择相似案例,该模块维护一个案例库,并根据问题中的关系的相似度选择相关案例。
随后在逻辑表达式的生成上,作者采用类似于 Prompt 的思想。首先采用一个 seq2seq 模型,将自然语言问题和案例库中与该问题相似的案例(自然语言问题+可执行逻辑表达式)拼接作为模型的输入,训练模型结合案例生成新问题的逻辑表达式,实现对案例的复用。
由于 Reuse Module 根据案例生成新的逻辑表达式,生成结果中的关系取自过往案例,同时知识图谱通常是不完整的,这就导致生成结果中的关系在知识图谱中不存在,导致逻辑表达式无法执行。因此作者提出一个 Revise Module,对生成结果中的关系进行修正。该模块通过将生成结果中的关系对齐到知识图谱中存在的最相似的关系实现对结果的修正。
由于 CBR-KBQA 根据案例库中的过往案例为新问题生成逻辑表达式,CBR-KBQA 可以通过向案例库添加新案例的方式泛化到训练过程中从未见过的关系上。
本文针对多跳 KGQA 问题,提出一种透明的框架提升多跳 KGQA 的效率和可解释性。现存的模型通常是通过预测多跳过程中的关系序列或者通过图神经网络提取知识图谱的隐式特征来解决多跳 KGQA 问题,前者由于推理路径的搜索空间太大而难以优化,后者则缺乏可解释性。本文作者提出的 TransferNet 则通过逐步计算,获取推理过程中每个节点激活的实体和关系解决 KGQA 问题,由于推理过程中的中间结果可以轻易被人类理解,具有较好的可解释性。
KBQA(Question Answering over Knowlegde Bases) 旨在根据结构化的知识图谱回答自然语言问题,该任务在现代的问答系统和信息检索系统中广泛应用。
由于自然语言问题与知识图谱中的推理链的不相容性,最近的 KBQA 方法更关注于图谱中的逻辑关系,忽略了图谱的节点和边上的文本语义信息。同时预训练模型虽然从大规模的语料中学习到了大量开放世界知识,但是这种知识是非结构化的,与结构化的知识图谱之间存在隔阂。为连接预训练语言模型与知识图谱,作者提出了三种关系学习任务来进行关系增强训练。经过这种训练,模型能够将自然语言表述与知识图谱中的关系对齐,同时能够跨过缺失的直接关系进行推理。
Multi-hop KGQA 要求跨越 Knowledge Graph, KG 的多个边进行推理,而且 KG 往往是不完整的,使 KGQA 更具挑战性。最近的研究有些使用额外的相关领域的语料解决 KG 的稀疏性问题,但是额外的语料是否可获取,以及相关性如何判别都是问题。KG embedding 作为另一个研究方向,被用于缺失连接预测以及 KG 补全,但是没有被直接用于 Multi-hop KGQA 问题。本文作者提出 EmbedKGQA,使用 KG embedding 以及 Question embedding 解决 KGQA 问题。