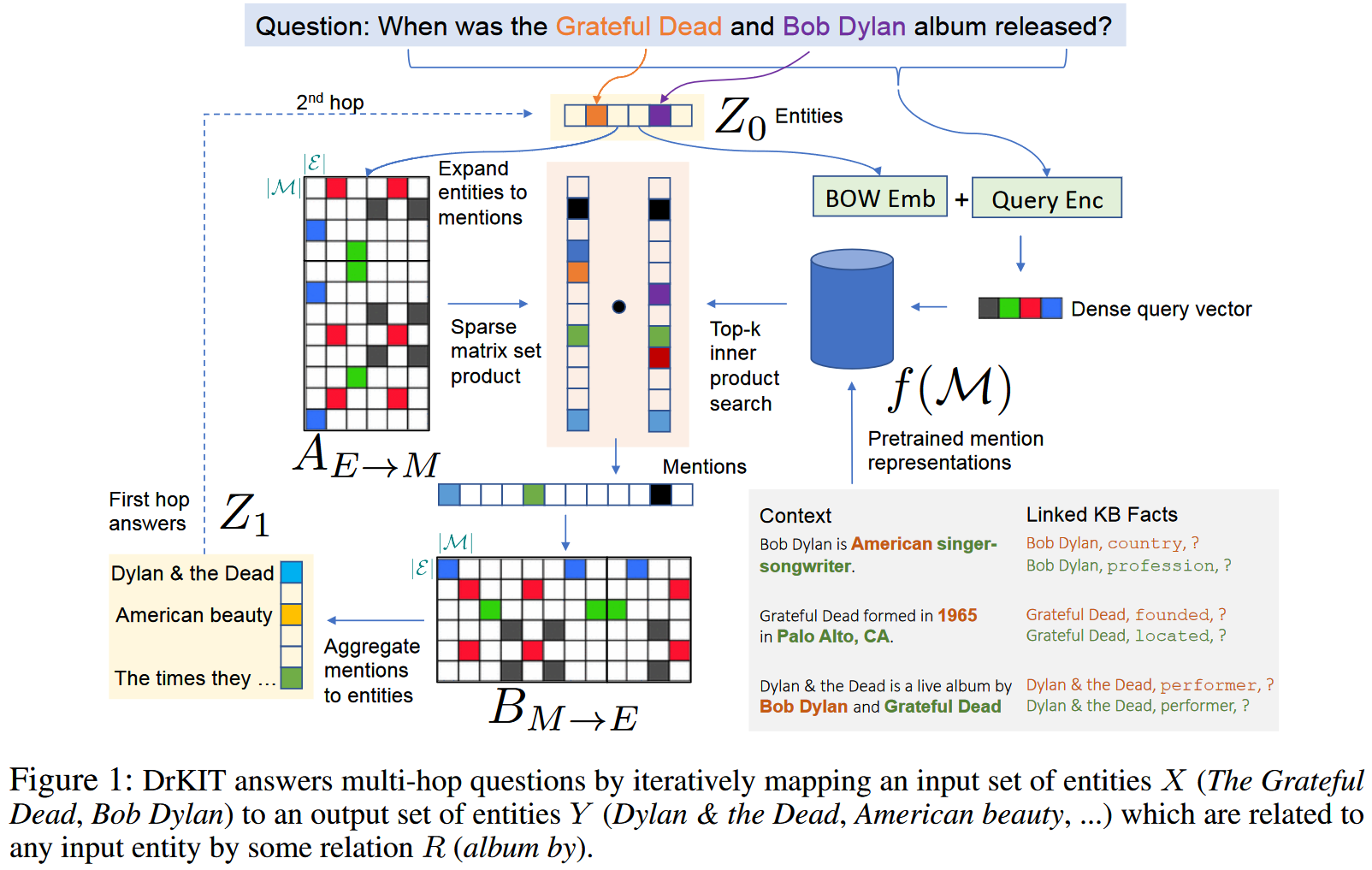
文章主要思想是利用包含事实的语料库作为虚拟知识库进行自然语言问答。2021 年 EMNLP 的文章 TransferNet: An Effective and Transparent Framework for Multi-hop Question Answering over Relation Graph 中提到的在 text form 关系的知识图谱上进行问答的思想与此类似。
作者首先在语料库上预先提取出所有的实体提及,并为其生成上下文表征,并基于处理的结果制作出实体->提及 以及提及->实体 的映射矩阵。随后在执行问答任务时,首先从问题中提取出涉及到的实体,编码成向量。然后通过与实体->提及 矩阵相乘初步选出提及,随后作者根据整个问题为提及评分,筛选掉与问题不相关的提及。筛选出的结果向量乘以提及->实体 矩阵得到推理的结果实体向量。对于 k-hop 的问题,只需迭代式地执行 k 次上述过程即可得到结果。
作者提出的主要思想是将语料库看作知识库,并基于此回答自然语言问题 q q q q q q z z z z z z z z z m m m m m m q q q q q q
与 z z z
与 z z z q q q
根据这些筛选过的提及,作者又将其转换到他们所指代的实体集 z ′ z' z ′ z ′ z' z ′
记语料库为 D = { d 1 , d 2 , . . . , d ∣ D ∣ } \mathcal{D} = \{d_1, d_2, ..., d_|\mathcal{D}|\} D = { d 1 , d 2 , . . . , d ∣ D ∣ } d k = ( d k 1 , d k 2 , . . . , d k L k ) d_k = (d_k^1, d_k^2, ..., d_k^{L_k}) d k = ( d k 1 , d k 2 , . . . , d k L k ) L k L_k L k E \mathcal{E} E m m m ( e m , k m , i m , j m ) (e_m, k_m, i_m, j_m) ( e m , k m , i m , j m ) k m k_m k m d k m i m , . . . , d k m j m d_{k_m}^{i_m}, ..., d_{k_m}^{j_m} d k m i m , . . . , d k m j m e m ∈ E e_m\in\mathcal{E} e m ∈ E M \mathcal{M} M ∣ M ∣ ≫ ∣ E ∣ |\mathcal{M}| \gg |\mathcal{E}| ∣ M ∣ ≫ ∣ E ∣
作者从概率语言模型出发,考虑一个仅以最终答案 a ∈ E a\in\mathcal{E} a ∈ E z 0 , z 1 , . . . , z T ∈ E z_0, z_1, ..., z_T\in\mathcal{E} z 0 , z 1 , . . . , z T ∈ E z 0 z_0 z 0 z T z_T z T a a a
Pr ( z t ∣ q ) = ∑ z t − 1 ∈ E Pr ( z t ∣ q , z t − 1 ) Pr ( z t − 1 ∣ q ) \Pr(z_t|q)=\sum_{z_{t-1}\in\mathcal{E}}\Pr(z_t|q, z_{t-1})\Pr(z_{t-1}|q)
Pr ( z t ∣ q ) = z t − 1 ∈ E ∑ Pr ( z t ∣ q , z t − 1 ) Pr ( z t − 1 ∣ q )
由于推理过程基于语料库,作者结合语料库中的实体提及 m m m Pr ( z t ∣ q , z t − 1 ) \Pr(z_t|q, z_{t-1}) Pr ( z t ∣ q , z t − 1 )
Pr ( z t ∣ q ) = ∑ m ∈ M ∑ z t − 1 ∈ E Pr ( z t ∣ m ) Pr ( m ∣ q , z t − 1 ) Pr ( z t − 1 ∣ q ) \Pr(z_t|q) = \sum_{m\in\mathcal{M}}\sum_{z_{t-1}\in\mathcal{E}}\Pr(z_t|m)\Pr(m|q,z_{t-1})\Pr(z_{t-1}|q)
Pr ( z t ∣ q ) = m ∈ M ∑ z t − 1 ∈ E ∑ Pr ( z t ∣ m ) Pr ( m ∣ q , z t − 1 ) Pr ( z t − 1 ∣ q )
上式中,Pr ( m ∣ q , z t − 1 ) \Pr(m|q, z_{t-1}) Pr ( m ∣ q , z t − 1 ) m m m q q q z t − 1 z_{t-1} z t − 1
Pr ( m ∣ q , z t − 1 ) ∝ 1 { G ( z t − 1 ) ⋅ F ( m ) > ϵ } ⏟ 共现提及展开 × s t ( m , z t − 1 , q ) ⏟ 相关性筛选 \Pr(m|q, z_{t-1})\propto \underbrace{\mathbb{1}\{G(z_{t-1})\cdot F(m) > \epsilon\}}_{\text{共现提及展开}}\times \underbrace{s_t(m, z_{t-1}, q)}_{\text{相关性筛选}}
Pr ( m ∣ q , z t − 1 ) ∝ 共现提及展开 1 { G ( z t − 1 ) ⋅ F ( m ) > ϵ } × 相关性筛选 s t ( m , z t − 1 , q )
上式中第一项被认为基于和上一步的中间实体 z t − 1 z_{t-1} z t − 1 q q q z t − 1 z_{t-1} z t − 1
除 Pr ( m ∣ q , z t − 1 ) \Pr(m|q, z_{t-1}) Pr ( m ∣ q , z t − 1 ) Pr ( z t ∣ m ) \Pr(z_t|m) Pr ( z t ∣ m ) m m m z t z_t z t
在实际实现时,作者使用矩阵计算实现上述模型。首先作者预计算语料库中所有实体和实体提及的 TFIDF 向量,并将其组织成一个稀疏矩阵 A E ← M [ e , m ] = 1 ( G ( e ) ⋅ F ( m ) > ϵ ) A_{E\leftarrow M}[e, m] = \mathbb{1}(G(e)\cdot F(m) > \epsilon) A E ← M [ e , m ] = 1 ( G ( e ) ⋅ F ( m ) > ϵ ) e e e m m m ϵ \epsilon ϵ A [ e , m ] = 1 A[e, m] = 1 A [ e , m ] = 1 z t − 1 z_{t-1} z t − 1 A E ← M A_{E\leftarrow M} A E ← M
对于相关性筛选,记 T K ( s t ( m , z t − 1 , q ) ) \mathbb{T}_K(s_t(m, z_{t-1}, q)) T K ( s t ( m , z t − 1 , q ) ) R ∣ M ∣ \mathbb{R}^{|\mathcal{M}|} R ∣ M ∣
对于提及到实体的映射,作者使用另一个稀疏矩阵 B M ← E B_{M\leftarrow E} B M ← E
综合上述过程,z t z_t z t
Z t = softmax ( [ Z t − 1 T A E ← M ⊙ T K ( s t ( m , z t − 1 , q ) ) ] B M ← E ) Z_t = \text{softmax}([Z_{t-1}^TA_{E\leftarrow M}\odot\mathbb{T}_K(s_t(m, z_{t-1}, q))]B_{M\leftarrow E})
Z t = softmax ( [ Z t − 1 T A E ← M ⊙ T K ( s t ( m , z t − 1 , q ) ) ] B M ← E )
其中 Z t Z_t Z t
上式的计算过程是可微的,同时由于 top-K 的限制,每个 hop 的计算最多产生 K 个实体,避免了多跳场景下的实体爆炸。
作者在下文介绍了上式计算中考虑矩阵稀疏性的效率,同时说明了 s t ( m , z t − 1 , q ) s_t(m, z_{t-1}, q) s t ( m , z t − 1 , q ) s t ( m , z t − 1 , q ) ∝ exp { f ( m ) ⋅ g t ( q , z t − 1 ) s_t(m, z_{t-1}, q)\propto \exp\{f(m)\cdot g_t(q, z_{t-1}) s t ( m , z t − 1 , q ) ∝ exp { f ( m ) ⋅ g t ( q , z t − 1 )
使用 PLM 编码 m m m m m m m m m f ( m ) = W T [ H i d ; H j d ] f(m) = W^T[H_i^d; H_j^d] f ( m ) = W T [ H i d ; H j d ]
使用 PLM 编码问题 q q q [ C L S ] [CLS] [ C L S ] q q q H q H^q H q
在此基础上,对于每一个 hop t = 1 , . . . , T t = 1, ..., T t = 1 , . . . , T H q H^q H q H s t q H_{st}^q H s t q H e n q H_{en}^q H e n q g ~ t ( q ) = V T [ H s t q ; H e n q ] \tilde{g}_t(q) = V^T[H_{st}^q; H_{en}^q] g ~ t ( q ) = V T [ H s t q ; H e n q ]
记所有实体的表征矩阵为 E ∈ R ∣ E × p ∣ E\in\mathbb{R}^{|\mathcal{E}\times p|} E ∈ R ∣ E × p ∣ Z t − 1 Z_{t-1} Z t − 1 Z t − 1 T E Z_{t-1}^TE Z t − 1 T E g t ( q , z t − 1 ) = g ~ t ( q ) + Z t − 1 T E g_t(q, z_{t-1}) = \tilde{g}_t(q) + Z_{t-1}^TE g t ( q , z t − 1 ) = g ~ t ( q ) + Z t − 1 T E
在上述计算过程中,作者发现直接使用 PLM 为实体生成表征效果不理想,仍需要使用知识图谱远程监督训练 PLM 改善实体表征。